DrivingGen
A Comprehensive Benchmark for Generative Video World Models in Autonomous Driving
ICLR 2026
Overview
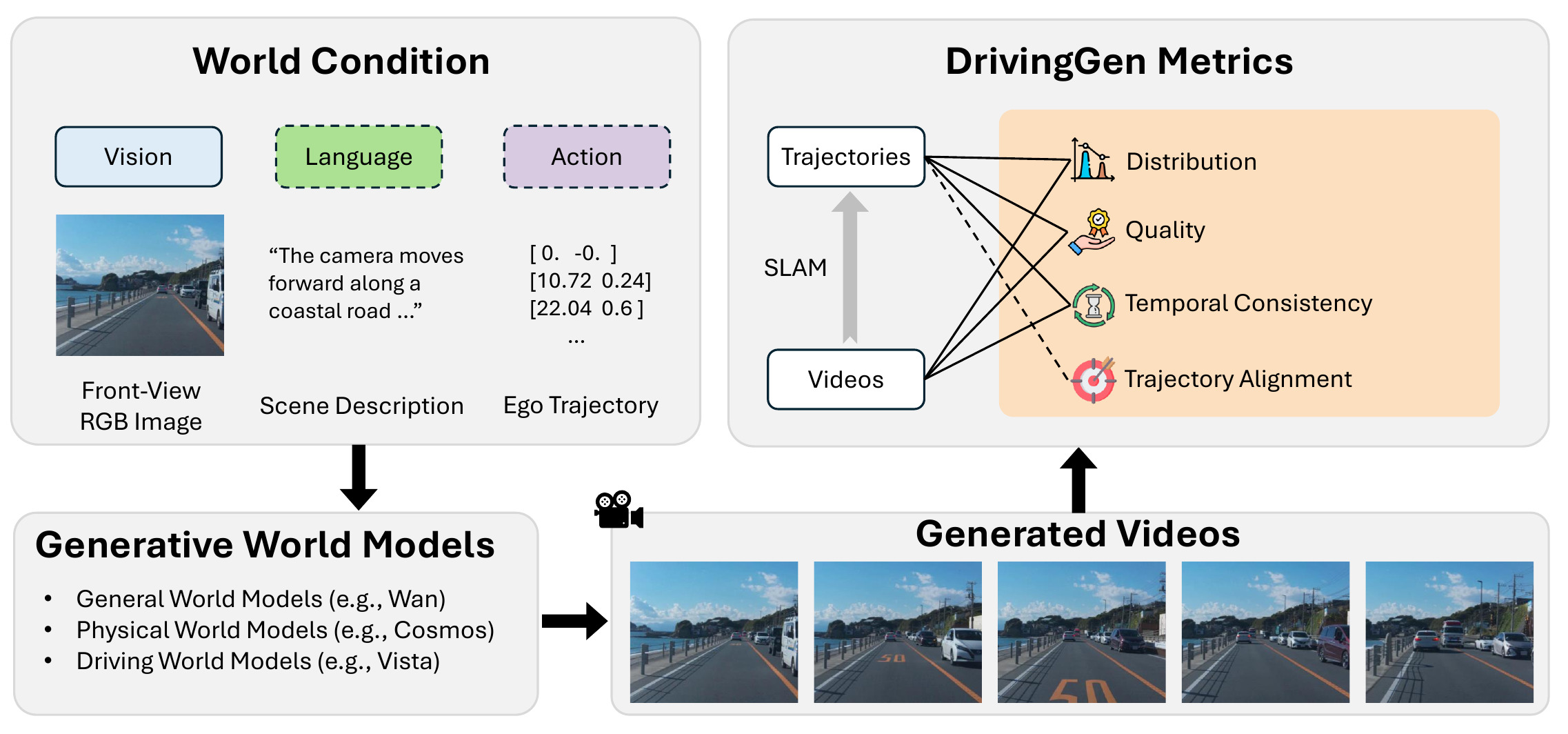
Distribution
How far is the generative distribution from the data distribution? We evaluate distributional closeness across both videos and trajectories, capturing complementary perspectives from visual perception and robotics.

The camera continues to capture the road ahead, showing the vehicles driving forward. The scene remains static, with no significant changes in the environment or camera movement...
Quality
How good are the generated videos and trajectories? To evaluate the fidelity of generated videos and trajectories in driving scenarios, we propose a comprehensive quality suite covering three aspects: subjective image quality, objective image quality, and trajectory quality.
The camera continues to face forward as the vehicle drives along the street. Pedestrians cross the zebra crossing, and vehicles, including a red bus and a white van, pass by. The scene remains dynamic with ongoing traffic and pedestrian activity....
Temporal Consistency
How temporally consistent is the generated world? We assess the temporal consistency of both videos and trajectories. For videos, we evaluate scene-level consistency, agent-level consistency, and explicitly emphasize abnormal agent disappearance. For trajectories, we measure the consistency of speed and acceleration over time.
The vehicle will continue driving forward, following the green traffic light. The camera will capture the road ahead, showing other vehicles and pedestrians as they move through the intersection. The sky will remain partly cloudy, and the sunset colors will gradually change as the day progresses....
Trajectory Alignment
The alignment of the trajectories underlying the generated videos with the conditioning (ego) trajectory is also critical, especially for trajectory-grounded video generation. To assess this, we propose two complementary metrics.

The camera, positioned inside a vehicle, captures a nighttime scene at an intersection. Initially, the view shows several cars waiting at a red light from the perspective of the car directly behind them. As the traffic light changes to green, the camera remains stationary but pans slightly to follow the movement of the vehicles as they begin to drive forward. The road is illuminated by streetlights, and other vehicles can be seen moving in different directions, creating a dynamic urban traffic flow. The camera angle provides a clear view of the intersection and the surrounding area, including traffic signals and road markings...
Abstract
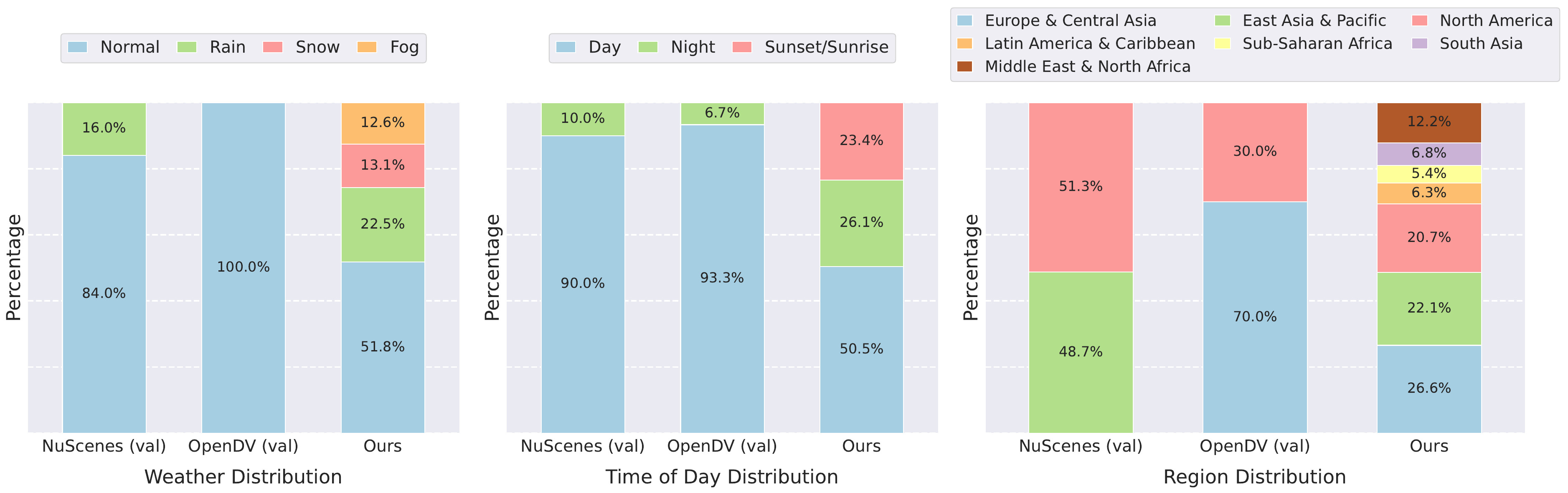
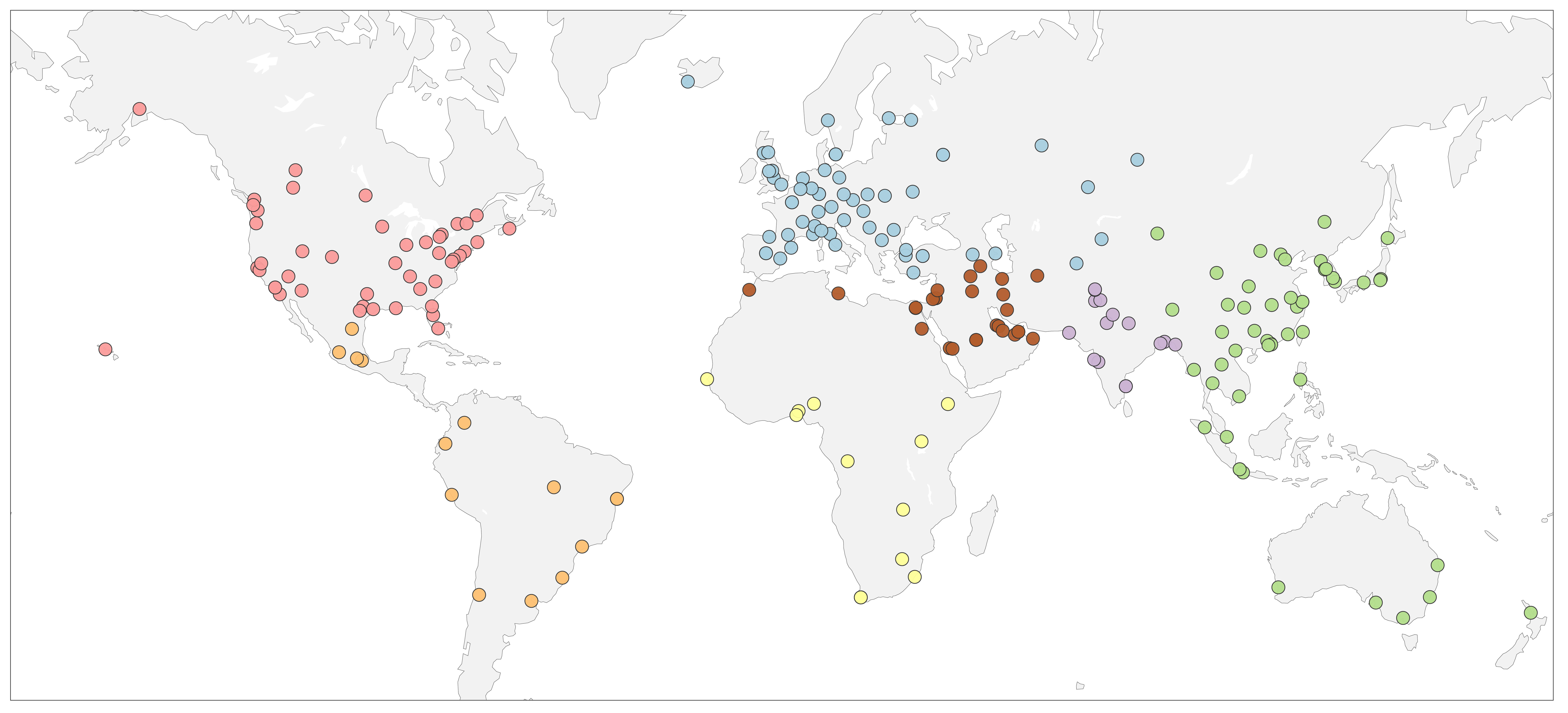
we present DrivingGen, the first comprehensive benchmark for generative driving world models. DrivingGen combines a diverse evaluation dataset—curated from both driving datasets and internet-scale video sources, spanning varied weather, time of day, geographic regions, and complex maneuvers—with a suite of new metrics that jointly assess visual realism, trajectory plausibility, temporal coherence, and controllability. Benchmarking 14 state-of-the-art models reveals clear trade-offs: general models look better but break physics, while driving-specific ones capture motion realistically but lag in visual quality. DrivingGen offers a unified evaluation framework to foster reliable, controllable, and deployable driving world models, enabling scalable simulation, planning, and data-driven decision-making.
Dataset

Evaluation Results
| Open-Domain Track Models |
Size | Distribution | Quality | Temporal Consistency | Avg. Rank | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| FVD | FTD | Subjective Quality |
Objective Quality |
Trajectory Quality |
Video Consist. |
Agent Consist. |
Agent Missing |
Trajectory Consist. |
|||
| Kling 2.1* | - | 693.4 | 26.73 | 0.5538 | 0.8018 | 0.6438 | 0.8945 | 0.7981 | 0.9442 | 0.5377 | 1 |
| Gen-3 Alpha Turbo* | - | 801.0 | 93.50 | 0.5456 | 0.8378 | 0.6535 | 0.8900 | 0.8170 | 0.9495 | 0.4788 | 2 |
| LTX-Video | 13B | 648.2 | 31.29 | 0.5215 | 0.8288 | 0.5562 | 0.8851 | 0.7449 | 0.8977 | 0.4517 | 3 |
| Wan2.2-I2V | 14B | 609.0 | 63.86 | 0.5348 | 0.6396 | 0.5983 | 0.8883 | 0.7514 | 0.9128 | 0.4639 | 4 |
| HunyuanVideo-I2V | 13B | 957.5 | 30.95 | 0.4921 | 0.7207 | 0.4613 | 0.8821 | 0.8008 | 0.9306 | 0.4157 | 5 |
| SkyReels-V2-I2V | 14B | 876.0 | 52.93 | 0.5134 | 0.7432 | 0.4799 | 0.8776 | 0.7329 | 0.9078 | 0.4326 | 7 |
| CogVideoX | 5B | 621.2 | 236.7 | 0.4932 | 0.6802 | 0.3856 | 0.8211 | 0.7581 | 0.7661 | 0.2949 | 12 |
| Cosmos-Predict2 | 14B | 524.1 | 83.20 | 0.4931 | 0.7568 | 0.5990 | 0.8597 | 0.5912 | 0.8657 | 0.3997 | 8 |
| Cosmos-Predict1 | 14B | 821.1 | 81.22 | 0.5083 | 0.7207 | 0.2723 | 0.8429 | 0.6789 | 0.8796 | 0.2631 | 13 |
| Vista | 2.5B | 675.7 | 54.66 | 0.4340 | 0.8468 | 0.6030 | 0.8565 | 0.6357 | 0.8211 | 0.4040 | 6 |
| VaViM | 1.2B | 1446.6 | 449.2 | 0.4691 | 0.8468 | 0.3118 | 0.9159 | 0.7721 | 0.9752 | 0.0914 | 9 |
| UniFuture | 3.0B | 774.3 | 50.66 | 0.4206 | 0.9054 | 0.4507 | 0.8799 | 0.5373 | 0.8310 | 0.3858 | 10 |
| GEM | 2.1B | 770.1 | 147.1 | 0.5168 | 0.8423 | 0.5398 | 0.8176 | 0.6099 | 0.7788 | 0.3392 | 11 |
| Drivingdojo | 2.3B | 810.4 | 126.74 | 0.4202 | 0.8333 | 0.4511 | 0.8480 | 0.6256 | 0.8303 | 0.2739 | 14 |
| Ego-Conditioned Track Models |
Size | Distribution | Quality | Temporal Consistency | Trajectory Alignment | Avg. Rank | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FVD | FTD | Subjective Quality |
Objective Quality |
Trajectory Quality |
Video Consist. |
Agent Consist. |
Agent Missing |
Trajectory Consist. |
ADE | DTW | |||
| Kling 2.1* | - | 320.5 | 23.74 | 0.5468 | 0.7838 | 0.6860 | 0.8929 | 0.8186 | 0.9712 | 0.5430 | 29.97 | 2310 | 1 |
| Gen-3 Alpha Turbo* | - | 555.9 | 24.72 | 0.5740 | 0.8604 | 0.6770 | 0.8747 | 0.7986 | 0.9466 | 0.4800 | 33.39 | 2749 | 3 |
| Wan2.2-I2V | 14B | 194.4 | 29.56 | 0.5084 | 0.6982 | 0.6419 | 0.8821 | 0.7561 | 0.9034 | 0.4849 | 27.39 | 1901 | 2 |
| LTX-Video | 13B | 378.1 | 61.09 | 0.4895 | 0.8604 | 0.5464 | 0.8705 | 0.7708 | 0.9020 | 0.4442 | 32.12 | 2505 | 6 |
| HunyuanVideo-I2V | 13B | 532.9 | 21.18 | 0.4741 | 0.6847 | 0.5542 | 0.8792 | 0.8240 | 0.9415 | 0.4771 | 33.80 | 2794 | 7 |
| CogVideoX | 5B | 307.1 | 166.6 | 0.4884 | 0.6937 | 0.4252 | 0.8167 | 0.7541 | 0.8981 | 0.3783 | 32.67 | 2413 | 10 |
| SkyReels-V2-I2V | 14B | 428.2 | 57.02 | 0.4764 | 0.6622 | 0.5028 | 0.8661 | 0.7208 | 0.8750 | 0.4322 | 31.54 | 2594 | 11 |
| Cosmos-Predict2 | 14B | 260.5 | 56.26 | 0.4756 | 0.8198 | 0.6424 | 0.8428 | 0.6707 | 0.8986 | 0.4108 | 22.38 | 1490 | 4 |
| Cosmos-Predict1 | 14B | 345.2 | 34.96 | 0.4783 | 0.7505 | 0.3761 | 0.8229 | 0.7423 | 0.7961 | 0.3343 | 34.47 | 3084 | 13 |
| Vista | 2.5B | 392.8 | 27.33 | 0.4146 | 0.8198 | 0.6047 | 0.8741 | 0.6417 | 0.8676 | 0.4366 | 19.70 | 1216 | 5 |
| UniFuture | 3.0B | 654.6 | 37.17 | 0.4006 | 0.9685 | 0.5353 | 0.8759 | 0.5525 | 0.8759 | 0.4165 | 20.21 | 1352 | 8 |
| VaViM | 1.2B | 1222 | 103.6 | 0.4910 | 0.8694 | 0.1936 | 0.9428 | 0.8290 | 0.9725 | 0.0984 | 41.92 | 3863 | 9 |
| Drivingdojo | 2.3B | 586.5 | 35.73 | 0.4264 | 0.8198 | 0.4131 | 0.8419 | 0.6940 | 0.8439 | 0.2776 | 25.50 | 2142 | 12 |
| GEM | 2.1B | 579.9 | 97.70 | 0.4484 | 0.8018 | 0.5085 | 0.7886 | 0.6180 | 0.7463 | 0.2983 | 25.73 | 1982 | 14 |
• This website is built upon WorldScore. We thank the authors of WorldScore that kindly open sourced the template of this website.








